LISO: Lidar-only Self-Supervised 3D Object Detection
TL;DR: Based on self-supervised lidar scene flow, we generate pseudo ground truth for lidar object detectors. Using the scene flow to track and refine the pseudo ground truth, we then train state-of-the-art lidar object detectors, improving the pseudo ground truth further and further with each round of tracking and retraining.
 Predicted boxes (single shot) by our method in
Predicted boxes (single shot) by our method in
Abstract
3D object detection is one of the most important components in any Self-Driving stack, but current state-of-the-art (SOTA) lidar object detectors require costly & slow manual annotation of 3D bounding boxes to perform well. We introduce a novel self-supervised method to train SOTA lidar object detection networks which works on unlabeled sequences of lidar point clouds only, which we call trajectory-regularized self-training. It utilizes a SOTA self-supervised lidar scene flow network under the hood to generate, track, and iteratively refine pseudo ground truth.
We demonstrate that our method works with two different networks on four different datasets, using the same hyperparameters.
Method:
Our method consists of 5 steps:
- Self-Supervised scene flow estimation
- Clustering scene flow & box fitting
- Box tracking and track optimization
- Object detector training
- Inference on train set & repetition from step 3 onwards
While the inital scene flow captures only moving objects, the object detector in step 4. generalizes from moving to all movable objects, since the single shot detector itself has no concept of “motion”.
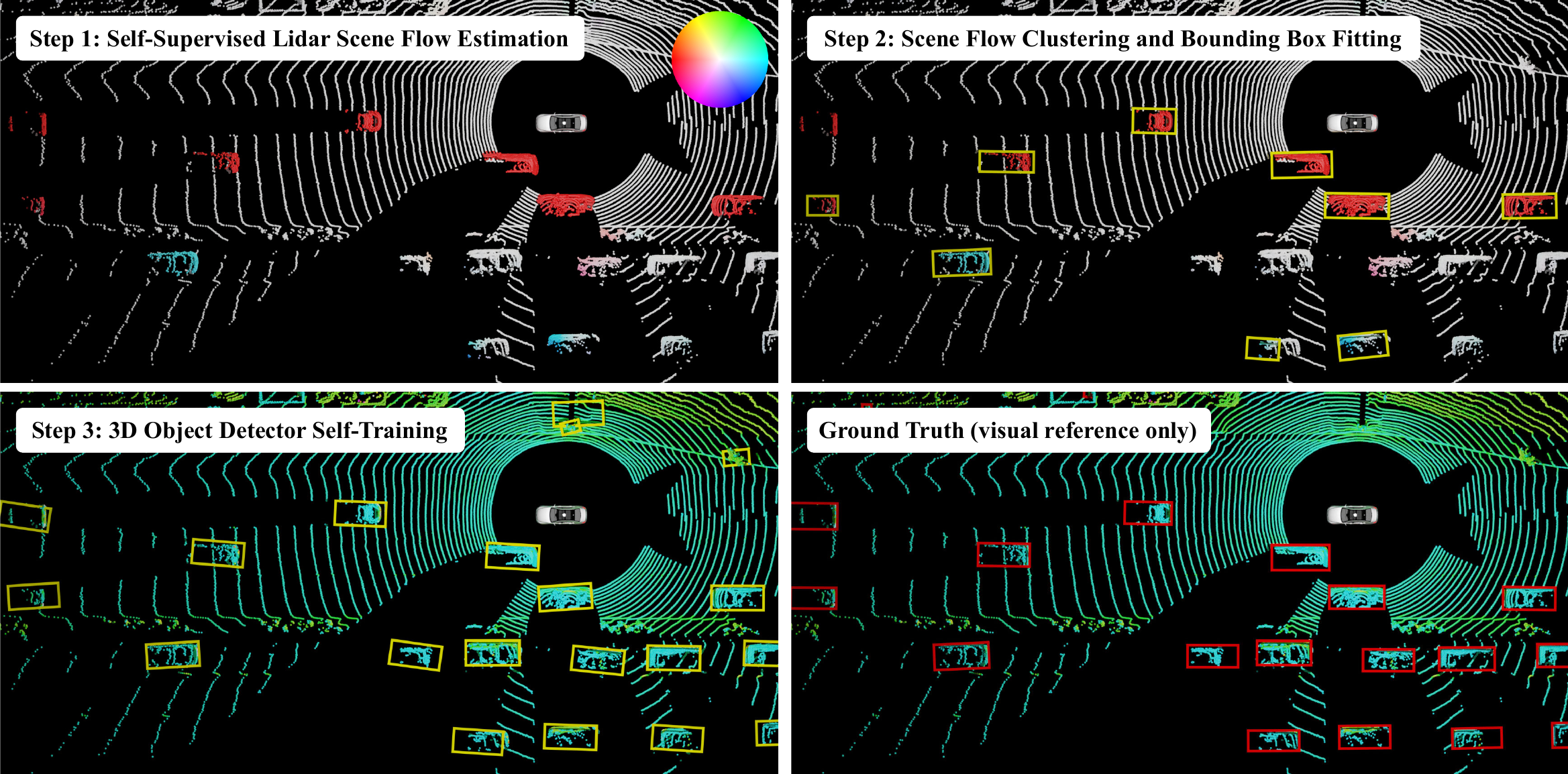
In the following, we explain each step based on a snippet from the KITTI dataset:
Step 1: Self-supervised Scene Flow
We train SLIM on consecutive lidar point clouds in an area of 120m x 120m around the ego vehicle, producing self-supervised lidar scene flow. The scene flow is then corrected for vehicle ego-motion, which we generate using the KISS-ICP lidar odometry pipeline.
Step 2: Clustering the Scene Flow
Using DBSCAN, we cluster the resulting scene flow and fit boxes around the clusters.
Step 3: Flow-based Tracking and Track Optimization
Using the Scene Flow from Step 1, we track the boxes, discarding tracks that are too short (time). We set the size of each box to the median of the observed box sizes in each track to deal with over/undersegmentation by DBSCAN and partial observations. Additionally, we align the orientation of the boxes along their tracks.
Step 4 & 5: Iterative Self-Training and Pseudo Groundtruth Regeneration
We now train a 3D object detector, using the boxes from the optimized tracks as pseudo ground truth. The object detector is trained on individual point clouds, not on any motion-signal like ego motion or scene flow. It is thus unable to distinguish moving from movable objects, leading to generalization to static objects in the process. This allows us to iteratively regenerate and improve the pseudo ground truth by using the flow-based tracking and track optimization from step 3.
Raw, unprocessed detections after several rounds of self-training:
Qualitative Results
Ground truth boxes in 

Cite
@inproceedings{Baur2024ECCV,
author = {Stefan Baur and Frank Moosmann and Andreas Geiger},
title = {LISO: Lidar-only Self-Supervised 3D Object Detection},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}