SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation
Stefan Baur*, David Emmerichs*, Frank Moosmann, Peter Pinggera, Bjorn Ommer and Andreas Geiger (*: equal conribution)

TL;DR: Based on the discrepancy between rigid sensor ego-motion estimate and a raw flow prediction, we generate a self-supervised motion segmentation signal and use it to train our network to perform self-supervised motion segmentation. This improves scene flow accuracy by enabling us to aggregate scene flow for static elements using Kabsch’s algorithm.
Abstract
Scene flow inherently separates every scene into multiple moving agents and a large class of points following a single rigid sensor motion. However, existing methods do not leverage this property of the data in their self-supervised training routines which could improve and stabilize flow predictions. Based on the discrepancy between a robust rigid ego-motion estimate and a raw flow prediction, we generate a self-supervised motion segmentation signal. The predicted motion segmentation, in turn, is used by our algorithm to attend to stationary points for aggregation of motion information in static parts of the scene. We learn our model end-to-end by backpropagating gradients through Kabsch’s algorithm and demonstrate that this leads to accurate ego-motion which in turn improves the scene flow estimate. Using our method, we show state-of-the-art results across multiple scene flow metrics for different real-world datasets, showcasing the robustness and generalizability of this approach. We further analyze the performance gain when performing joint motion segmentation and scene flow in an ablation study. We also present a novel network architecture for 3D LiDAR scene flow which is capable of handling an order of magnitude more points during training than previously possible.
Method
Network
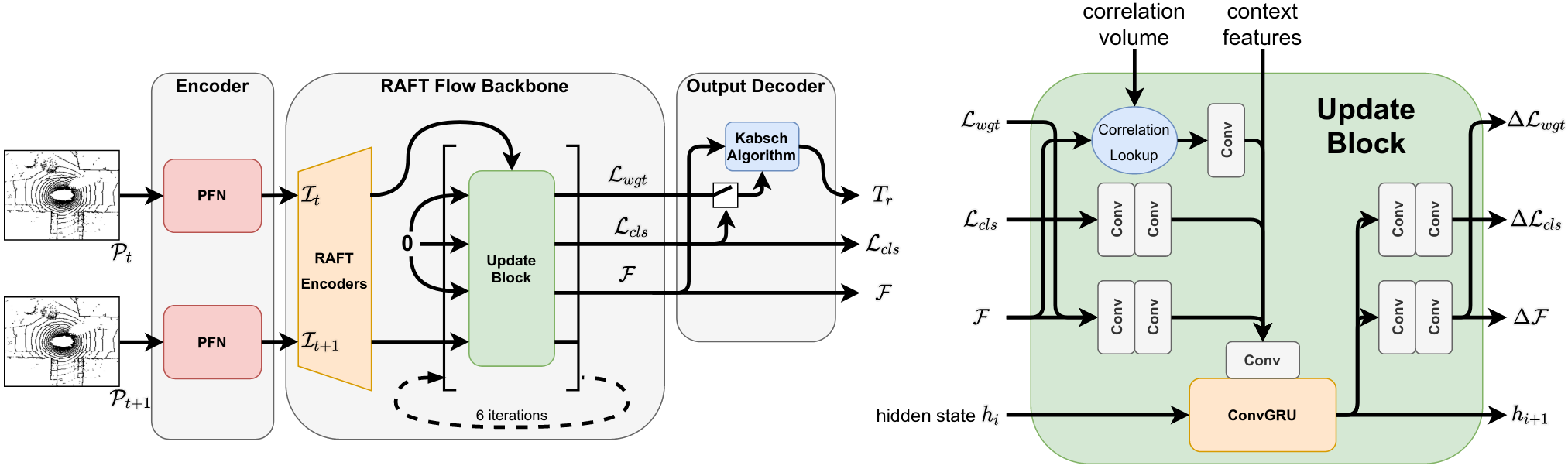
The two input point clouds are separately encoded into a BEV pseudo-image using the Pillar Feature Net. At the core of our backbone network is an update block acting recursively on a hidden state and a flow prediction, producing a more refined and accurate flow with every iteration: We adapt RAFT to handle flow prediction and iteratively update two additional logits, used to classify the points as stationary or moving w.r.t. the world frame as well as confidence weights used for static aggregation. In order to regularize and improve the flow prediction on the static scene, flow estimates for points classified as still are aggregated into a single coherent rigid-motion odometry transform, using Kabsch’s algorithm. To decide whether a point is stationairy or moving, our model keeps track of a global classification threshold through moving averages. Points predicted to be stationary then use the flow from the aggregated rigid ego-motion transform, all other points use the raw flow prediction from the network.
Losses
- k-NN Loss: First and foremost we use a k-NN loss as a self-supervision signal for our flow estimation as is done by earlier works for self-supervised scene flow.
- Rigid cycle consistency: We apply our network to both input point clouds and predict flow also on the reversed order, giving us access to the prediction of the inverse rigid motion. For accurate predictions, these two rigid transforms are the exact inverses to each other.
- Artificial Labels: The classification logits are trained using a self-supervised loss based on the k-NN errors.
Presentation Video
Qualitative Results
Motion Segmentation: Left Groundtruth, right prediction. Higher dynamicness is brighter.

Cite
@INPROCEEDINGS{Baur2021ICCV,
author = {Stefan Baur and David Emmerichs and Frank Moosmann and Peter Pinggera and Bjorn Ommer and Andreas Geiger},
title = {SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}